

How Linear Regression can help make forecasts more accurate
by Philip Stubbs, Drakelow Consulting
In this article, I look at Linear Regression, a powerful statistical technique that can help you forecast more accurately when there is a strong relationship between what you are trying to forecast and one or more drivers.
1. Introduction
We make forecasts because there is variation in our demand lines: if there were no variation, then there would be no need to make forecasts. Some variation can
be adequately modelled using smoothing, trend and seasonality techniques. Yet in many situations, causes of variation exist arising from specific, known external
factors. For example, sales of a product can rise and fall depending on advertising spend. Also, the number of emails arriving at a service centre can depend
on the number of sales made in previous weeks.
One technique that can help understand these relationships is Linear Regression. It provides powerful insight into what might be the causes of variation, and provides an equation that can be coded into a model to quickly generate forecasts. Yet such a cause-and-effect forecasting model should only be used in certain circumstances, and these are explained within this article.
2. Regression with single independent variable
Consider the following forecasting problem, for an inbound sales contact centre. We know the historical weekly values of inbound calls, and the number of
sales made in each week. Eleven weeks of call volume and sales volume are known, and the Marketing department has provided an estimate of the number of sales
that will be made in weeks 12 to 14. A forecast of call volume is required for weeks 12 to 14.
| Week | Sales | Calls |
| 1 | 9346 | 54613 |
| 2 | 24913 | 91629 |
| 3 | 20468 | 80490 |
| 4 | 28594 | 117022 |
| 5 | 23402 | 97796 |
| 6 | 20974 | 81850 |
| 7 | 11911 | 59062 |
| 8 | 29588 | 108800 |
| 9 | 13811 | 64013 |
| 10 | 19319 | 74713 |
| 11 | 14057 | 59324 |
| 12 | 14906 | ? |
| 13 | 21092 | ? |
| 14 | 14558 | ? |
The simplest way for most people to perform Linear Regression is within Excel.
Therefore, within Excel, enter the data from the table, and create a scatter chart of the two variables for the eleven known weeks. Ensure that the independent variable (Sales) is on the x axis at the bottom, and the forecast variable (Calls) is on the y axis on the left. Review the relationship in the chart: if you have something that resembles a straight line then a Linear Regression may be worth pursuing. With our example data, you should end up with a chart that looks like this, with each data point representing one week:
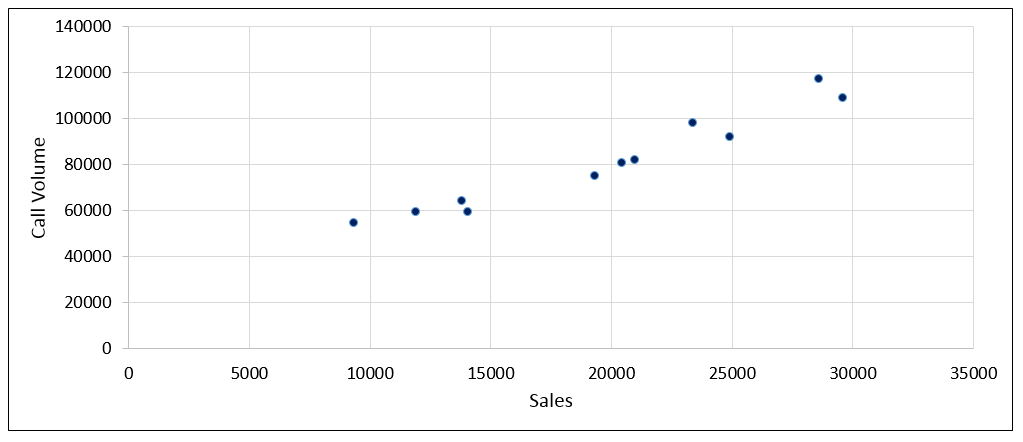
We see that when sales is low, so too is call volume. And as Sales increases, so too does the call volume. The relationship is broadly a striaght line
The next step is to apply the Linear Regression technique, which places a best-fit line through these data points, and delivers the equation of a line, in the format y=mx+c.
In Excel, you can do this by right-clicking over the data points, then click on “Add Trendline”, and then clicking on the “Display equation on chart” option. You should end up with the chart looking like this:
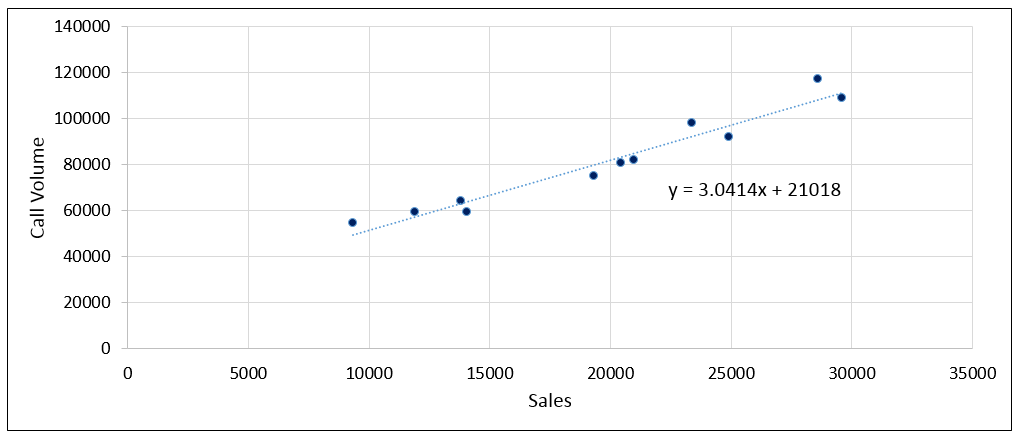
The equation that the regression comes back with is y = 3.0414x + 21018
Since y represents Calls, and x represents Sales, we can rewrite the equation as:
Calls = (3.0414 * Sales) + 21018
The number 21018 represents the number of calls that we would receive if Sales were zero. In statistics, this is known as the intercept, and is the point where the best-fit line will strike the y-axis.
The number 3.0414 represents the number of calls we receive for every unit increase of Sales. This is the gradient of the best-fit line, ie its steepness.
The gradient (3.0414) and the intercept (21018), the numbers in the equation, are known as the parameters of the model. Very often these parameters are informative. In this example, the number 21018 represents a number of calls that are not directly related to sales. It might launch an investigation to understand ways to eliminate or automate these calls without affecting the number of sales made. Now let’s see how we can use this equation for forecasting.
3. Estimating the forecasts
The equation above can be included as a formula within a spreadsheet, as part of a forecasting model. For week 12, Marketing has estimated that Sales is likely to be 14906.
If we place this
into the above equation, we can estimate that the number of calls is 66,353 calls. We can complete the table by also calculating forecasts for weeks 13 and 14.
| Week | Sales | Calls |
| 12 | 14906 | 66353 |
| 13 | 21092 | 85167 |
| 14 | 14558 | 65295 |
4. Use Explanative models with care
A driver-based model such as this is an Explanative model, ie one that explains the variation in call volume through an independent variable (Sales). Yet in order to use
an Explanative model, you must rely on three assumptions, and these MUST be in place before you consider using an Explanative model. Let’s look at them one at a time.
a. There must be a good historical relationship between the forecast variable and the input variable
When reviewing client forecasting models, I regularly see driver-based models where the relationship is very poor. Very often the relationship between the two variables
has not even been tested. When the relationship is examined, it is often a very poor relationship – undermining the logic of the forecasting model.
b. There must be reasonable belief that this relationship will continue to exist into the future
If you do find a good relationship in the past, then great! But in order to be useful for accurate forecasting, you must be convinced that the relationship will continue to
hold into the future. Alas, many things may cause a relationship to cease: the launch of a new product/service; a price change; or the implementation of new technology, such
as an automated service.
c. You must be able to acquire good forecasts of the independent variable
If the forecasts of the independent variable that are supplied to you are poor, then the accuracy of your forecasting model will be undermined. It’s the old Garbage-In-Garbage-Out
rule. If you use an Explanative model, you must ensure that the indpendent variable forecasts are accurate. This means getting regular, up-to-date forecasts from your supplier,
and providing feedback to maximise accuracy.
You should only be using an Explanative model if you are confident in all three of these assumptions. By failing to ensure that these three assumptions are in place, organisations can end up using models that give forecasts that are very different from what will actually happen. This can lead to unnecessary cost or revenue risk from missed customer opportunities.
If one of these three assumptions looks dodgy, then you must either improve the Explanative model, or reject Explanative modelling entirely, and just use the historical values of the forecast variable itself for making predictions. I’ve seen countless examples of Explanative models whose accuracy can be outperformed by a simple model based on averages.
5. Further regression within Excel
What I have demonstrated is just the simplest form of regression model. There are many extensions to this. Here are four further regression extensions that can be performed
in Excel. (For reasons of space, I am not giving in-depth examples here, but please get in touch if you would like to find out more.)
a. Multiple Regression is where two or more independent variables are tested to find a relationship potentially useful to predict the forecast variable. In order to perform such multiple regression within Excel, then install the Analysis ToolPak (standard within Excel), or use the array function LINEST.
Always study the statistical significance of the variables, since only those that are statistically significant should be included. Including spurious variables (known as overfitting) may reduce the model’s predictive power. To reduce the risk of overfitting, it is recommended to test the accuracy of different models on set-aside data that has not been used to estimate the model’s parameters.
b. Lags can be applied to the model, which will provide an improvement if there is a time delay between the driver and the forecast variable. For example, where the number of inbound calls are linked to not only this week’s sales, but also to the previous week’s sales. An example of this I saw recently was in a retail email centre, where a lagged regression model demonstrated that it was statistically significant to take account of four of the last five weeks’ sales as input variables. This helped make forecasting more accurate but also provided useful insight into how many weeks after the sale that the emails were being sent.
c. If you find a relationship that is not a straight-line, then it may be necessary to apply a statistical transformation in Excel to the input variable prior to performing the regression in order to achieve a straight-line relationship. One example of this is a logarithmic transformation.
d. After fitting a regression model, it is useful to study the residuals, which are the deviations between the actual value and the modelled value. You may notice a pattern in the residuals, called autocorrelation, where the value of the residuals demonstrate a relationship to their previous values. If you spot this, then a further amendment to the model can make it more accurate.
All of these four extensions to regression can be performed within Excel, yet there are many further regression modelling opportunities using statistical software such as R or SAS. Further, you can try fitting non-linear models with a terrific procedure in SAS called nlin.
Regression is an excellent tool to study and master before venturing into the world of Machine Learning. In fact, many Machine Learning texts include regression as a Machine Learning technique. Strictly speaking, regression is a statistical inference tool, rather than a Machine Learning tool. Yet many view the distinction between such statistical and machine learning techniques as an unhelpful, artificial boundary.
6. Conclusion
If you are new to regression, I hope you apply the technique and find some useful relationships to explain demand variation within your own data. But please ensure that the
three assumptions are in place before implementing an Explanative model to forecast demand.
Drakelow Consulting offers full support to business wishing to improve their forecasting and planning capability, including improving data, models and processes. We can also provide tailored coaching and training to ensure your analysis teams have the skills and experience required to deliver the accuracy you desire.
If you would like to discuss how to improve the accuracy and usefulness of your forecasting, across any or all of these fundamentals, then please contact me at philip@drakelowconsulting.com
Recommended Reading:
“Forecasting Methods and Applications” (3rd edition) by Makridakis, Wheelwright & Hyndman (Wiley)
“An Introduction to Statistical Learning” by James, Witten, Hastie & Tibshirani (Springer)